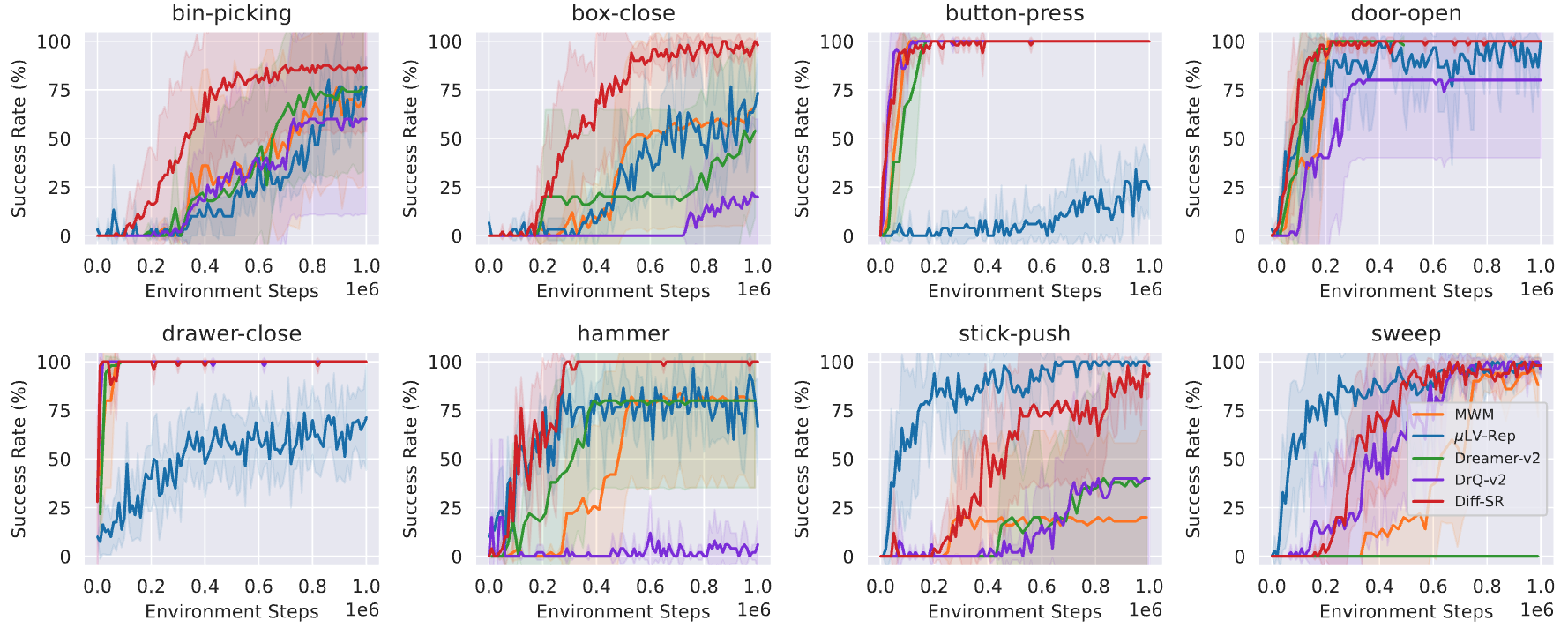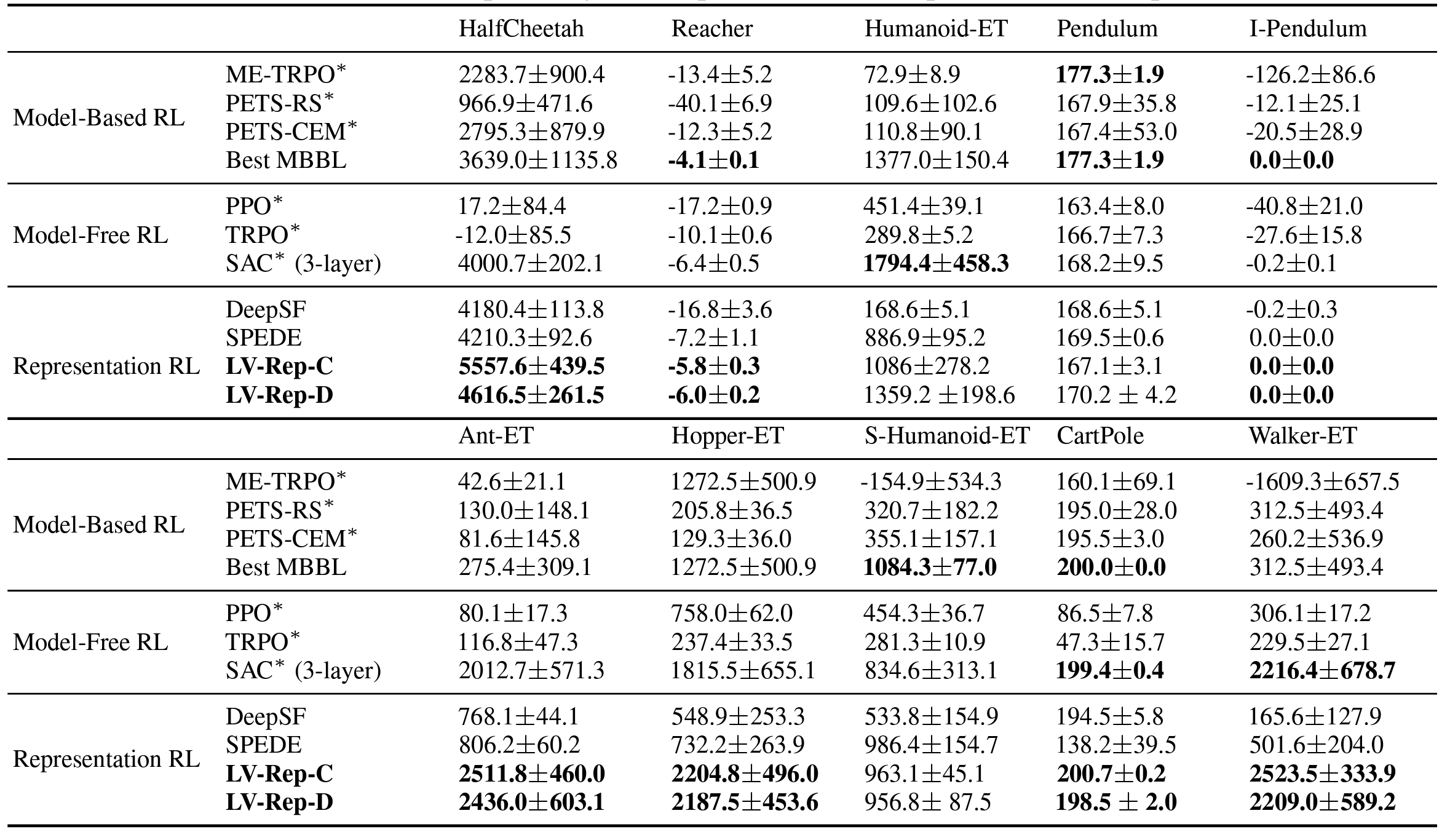
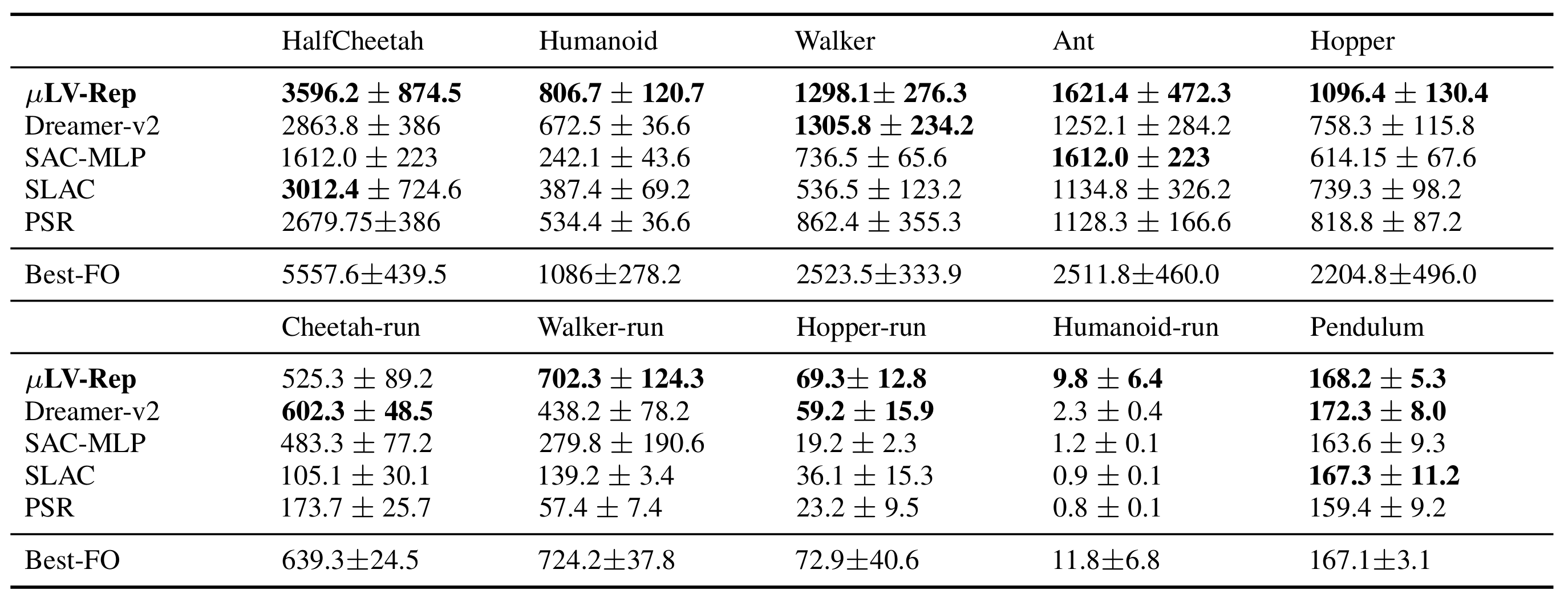
 Finally, this figure provides learning curves of LV-Rep-C and LV-Rep-D in comparison to SAC, which clearly shows that comparing to the SOTA (state-of-the-art) model-free baseline SAC, LV-Rep enjoys great sample efficiency in these tasks.
Finally, this figure provides learning curves of LV-Rep-C and LV-Rep-D in comparison to SAC, which clearly shows that comparing to the SOTA (state-of-the-art) model-free baseline SAC, LV-Rep enjoys great sample efficiency in these tasks.
We address the lingering computational efficiency issues in representation learning for linear MDPs. We provide solutions to the aforementioned difficulties, bridge the gap between theory and practice, and eventually establish a sound yet practical foundation for learning in linear MDPs. More specifically:
- We clarify the importance of the normalization condition and propose a variant of linear MDPs wherein it is easy to enforce normalization;
- We develop the ConTrastive Representation Learning algorithm, CTRL, that can implicitly satisfy the density requirement;
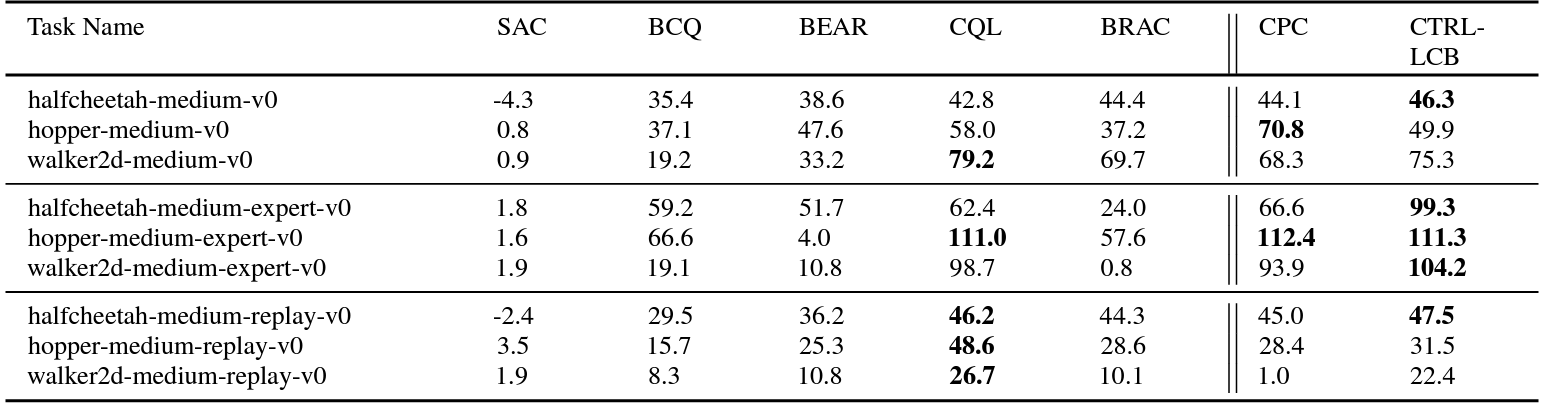
- We incorporate the representation learning techniques in optimistic and pessimistic confidence-adjusted RL algorithms, CTRL-UCB and CTRL-LCB, for both online and offline RL problems, and establish their sample complexities respectively;
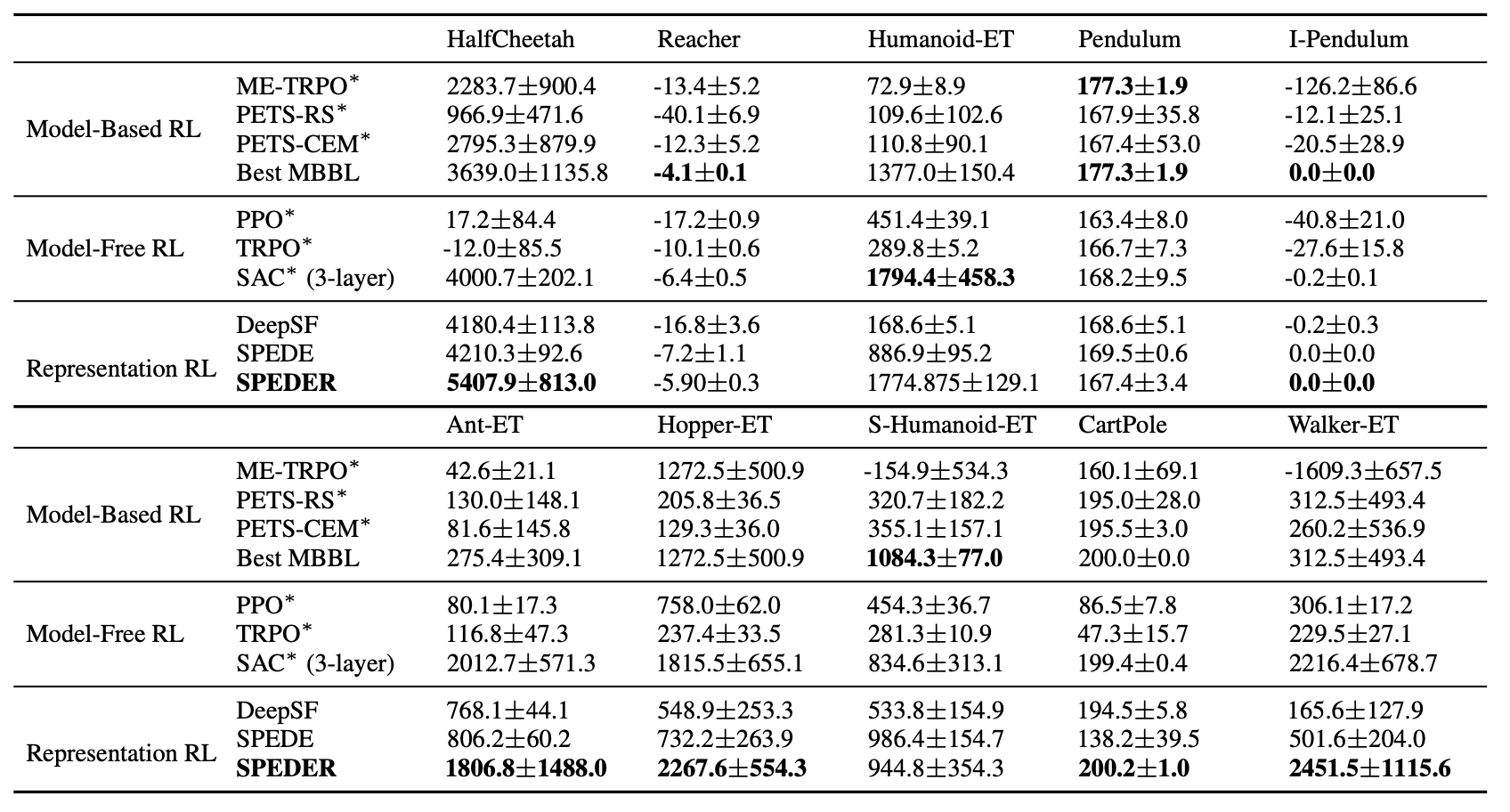
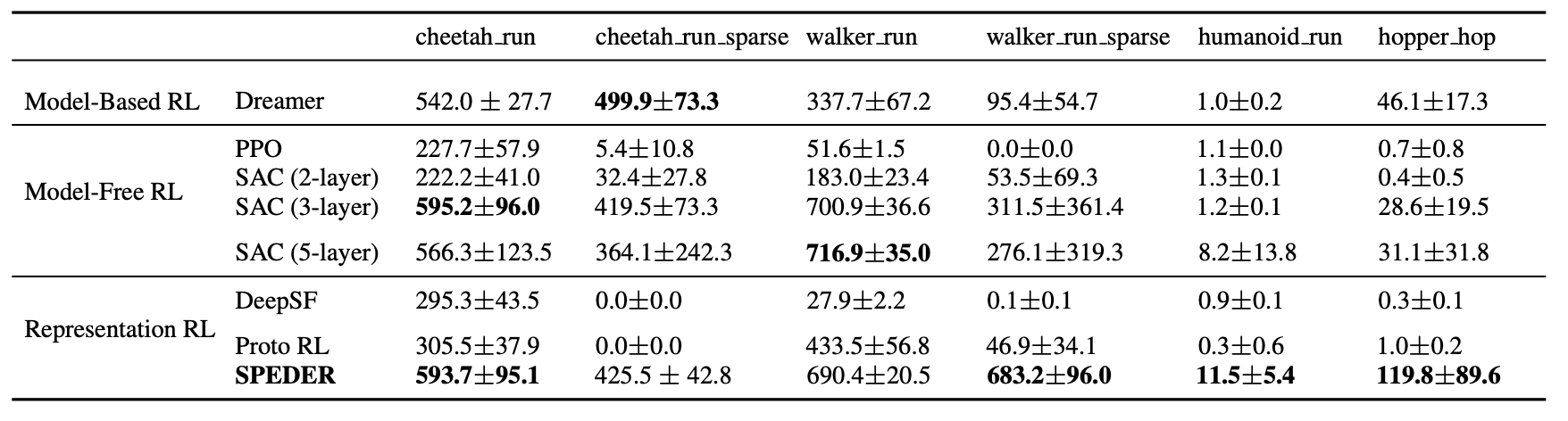
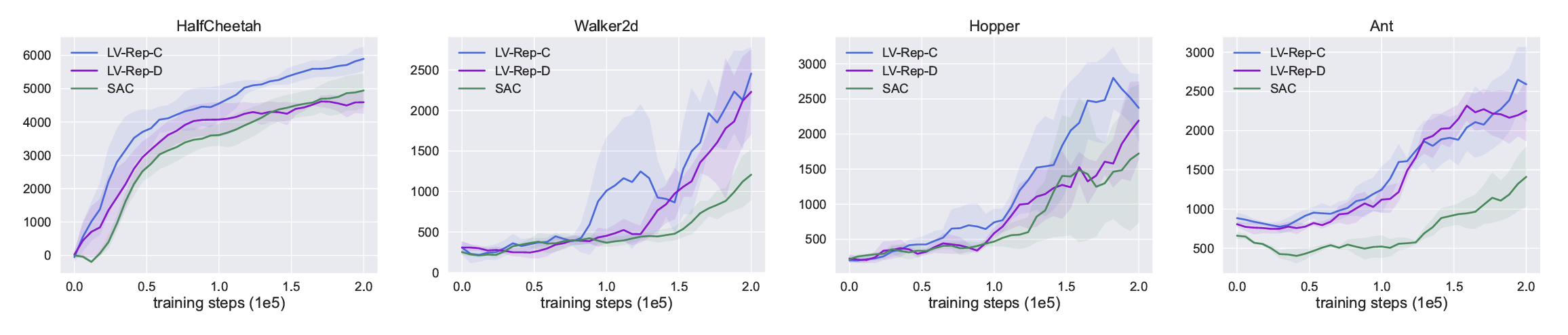
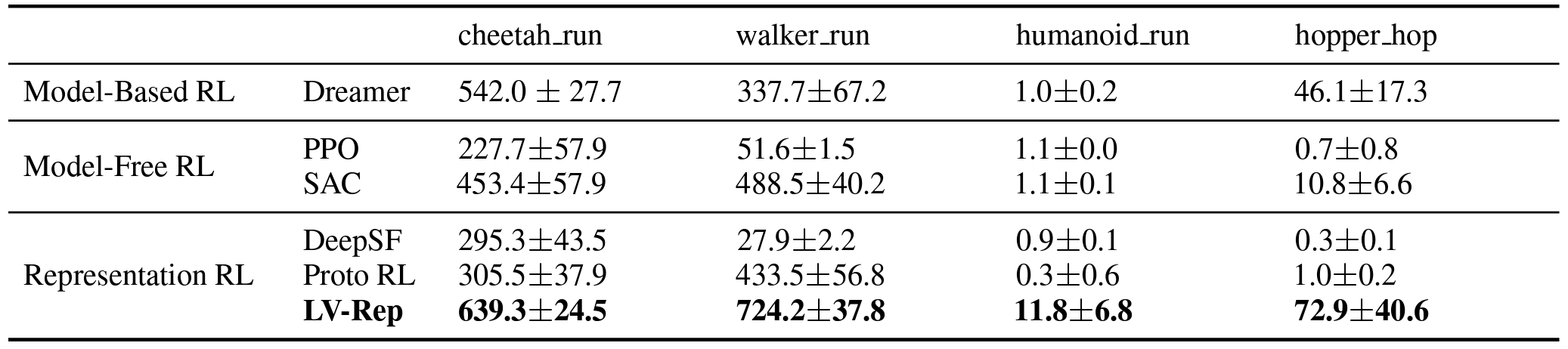
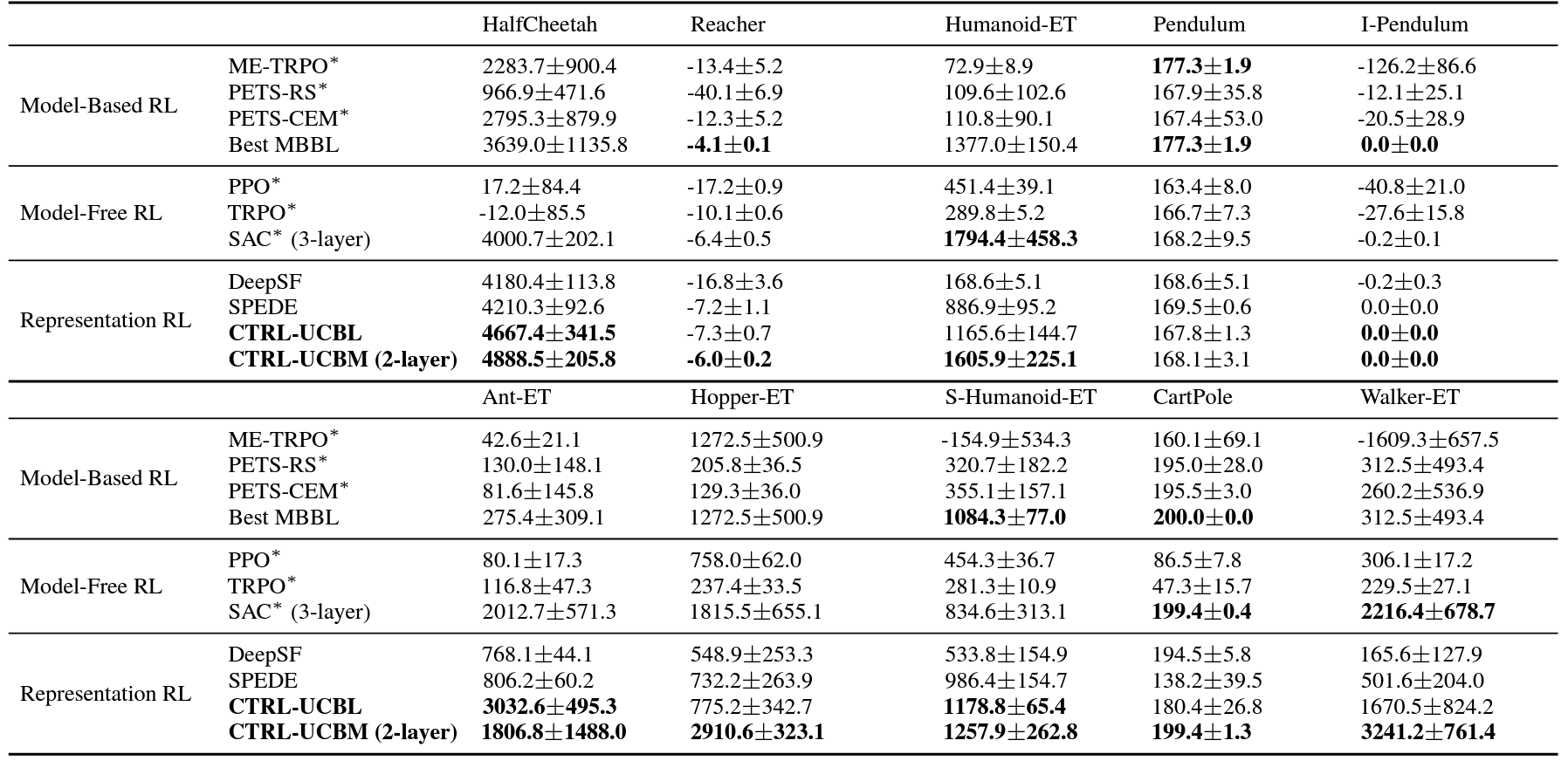
- We conduct a comprehensive comparison to existing state-of-the-art model-based and model-free RL algorithms on several benchmarks for the online and offline settings, demonstrating superior empirical performance of the proposed CTRL.

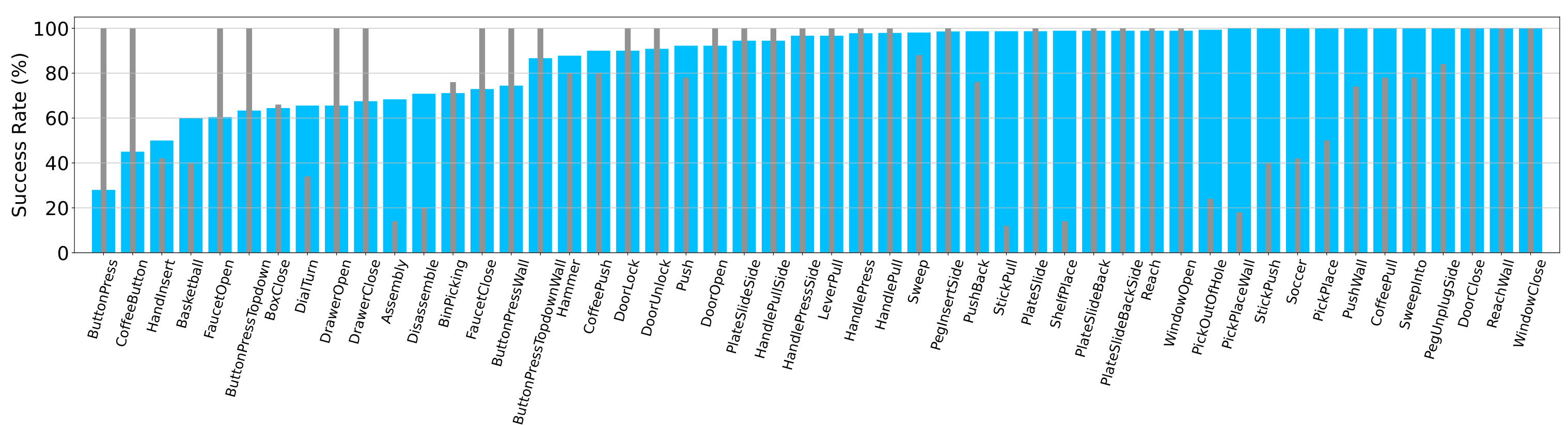
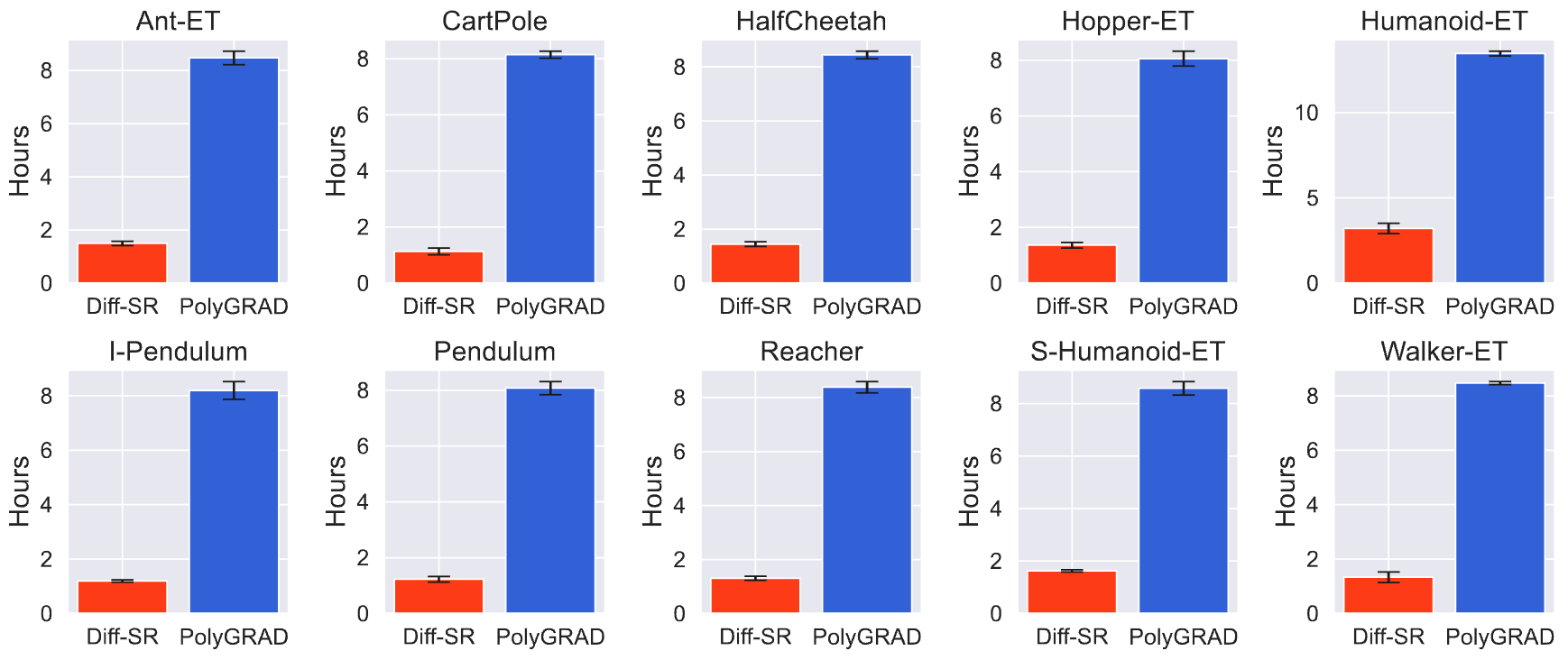
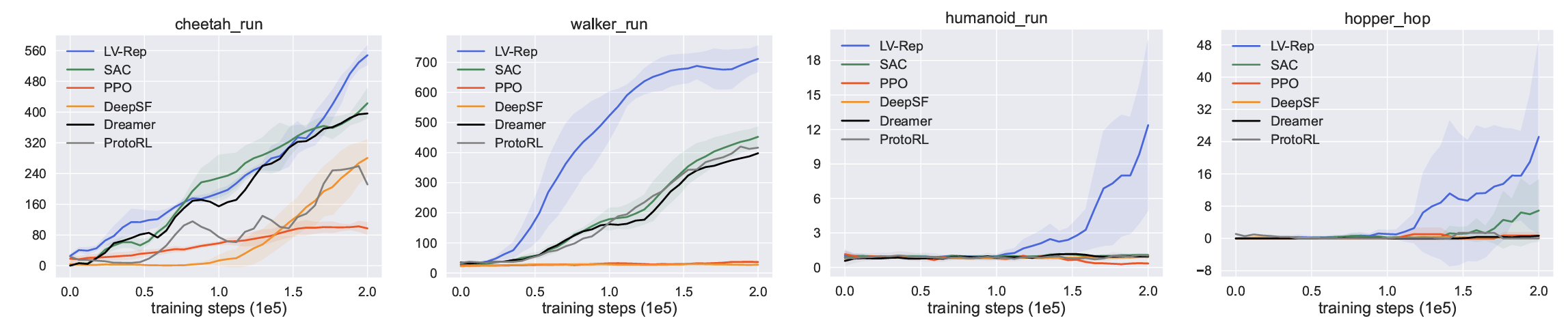
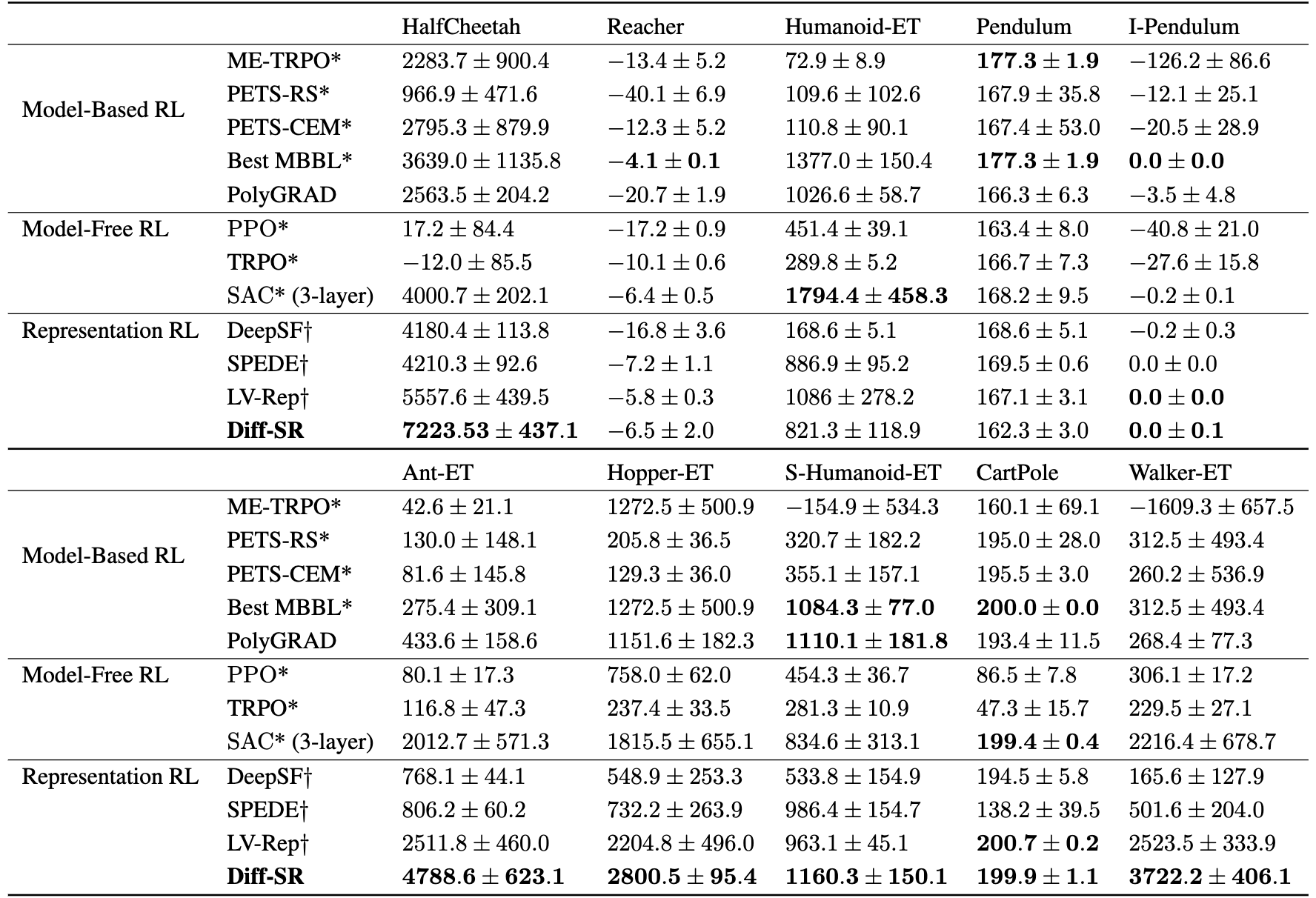 Besides its superior performance, Diff-SR does not require sampling from the diffusion model while still leverages the flexibility of diffusion models. This leads to 4x faster training speed compared to other diffusion-based RL methods, as we observed in our experiments (see the next figure).
Besides its superior performance, Diff-SR does not require sampling from the diffusion model while still leverages the flexibility of diffusion models. This leads to 4x faster training speed compared to other diffusion-based RL methods, as we observed in our experiments (see the next figure).